 download the Java source code for the
multithreaded webcrawler
download the Java source code for the
multithreaded webcrawlerAndreas Heß // Webcrawler
Here you can...
More or less in this case means that you have to be able to make minor adjustments to the Java source code yourself and compile it. You will need the Sun Java 2 SDK for this.
This web page discusses the Java classes that I originally wrote to implement a multithreaded webcrawler in Java. To understand this text, it is therefore necessary to
This code is in the public domain. You can do with the code whatever you like, and there is no warranty of any kind. However, I appreciate feedback. So feel free to send me an email if you have suggestions or questions, or if you have made modifications or extensions to the source code.
Why would anyone want to program yet another webcrawler? True, there are a lot of programs out there. A free and powerful crawler available is e.g. wget. There are also tutorials on how to write a webcrawler in Java, even directly from Sun.
Although wget is powerful, for my purposes (originally: obtaining .wsdl-files from the web) it required a webcrawler that allowed easy customization. The task would probably have been feasible with wget, but it was just easier to write my own stuff with Java. Besides, the whole multithreading stuff I wrote originally for the webcrawler could be reused in another context.
Sun's tutorial webcrawler on the other hand lacks some important features. For instance, it is not really multithreaded (although the actual crawling is spawned off in a separate thread). And for learning purposes, I think Sun's example distracts the user a bit from the actual task because they use an applet instead of an application.
Webcrawling speed is governed not only by the speed of ones own internet connection, but also by the speed of the sites that are to be crawled. Especially if one is crawling sites from multiple servers, the total crawling time can be significantly reduced, if many downloads are done in parallel.
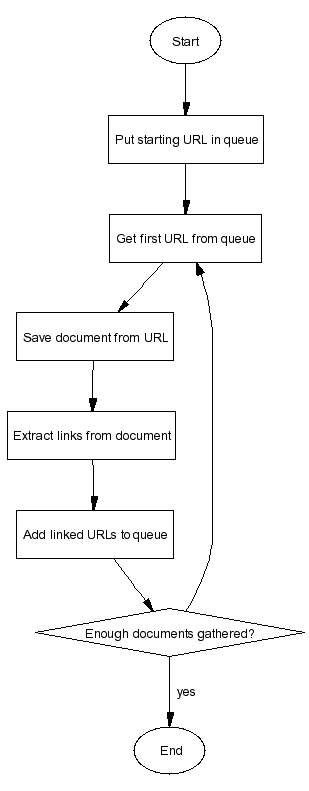 Webcrawling can be regarded as processing items in a queue. When
the crawler visits a web page, it extracts links to other web
pages. So the crawler puts these URLs at the end of a queue, and
continues crawling to a URL that it removes from the front of the
queue.
Webcrawling can be regarded as processing items in a queue. When
the crawler visits a web page, it extracts links to other web
pages. So the crawler puts these URLs at the end of a queue, and
continues crawling to a URL that it removes from the front of the
queue.
It is obvious, that every algorithm that just works by processing items that are independent of each other can easily be parallelized. Therefore, it is desirable to write a few classes that handle multithreading that can be reused. In fact, the classes that I wrote for web crawling originally were reused exactly as they are for a machine learning program.
Java provides easy-to-use classes for both multithreading and handling of lists. (A queue can be regarded as a special form of a linked list.) For multithreaded webcrawling, we just need to enhance the functionality of Javas classes a little. In the webcrawling setting, it is desirable that one and the same webpage is not crawled multiple times. We therefore do not only use a queue, but also a set that contains all URLs that have so far been gathered. Only if a new URL is not in this set, it is added to the queue.
We may also want to limit either the number of webpages we visit or the link depth. The methods in the queue interface resemble the desired functionality.
Note that if we limit the depth level we need more than one queue. If we only had one queue, the crawler could not easily determine the link depth of the URL it is just visiting. But regardless of the link depth we allow, two queues are sufficient. In this case, we allow the crawler to only fetch URLs from queue 1 and add URLs to queue 2. When all URLs in queue 1 are processed, we switch the queues.
Because of the generality of the problem, we can allow general Java Objects to be stored in the actual implementation of the queue.
As mentioned above, Java has a good interface for handling threads. However, in our special case, we can add a little more generic functionality. In our case, we want to make use of a number of threads that process items from the queue. A 'controller' should create new threads, if and only if there are still items in the queue to process and if the total number of threads does not exceed an upper bound.
In our implementation of such a thread controller, we provide the controller class on construction — among other parameters — with the class object for the thread class the queue. The queue should be pre-filled with at least one item. We require from our thread class, that it implements the run method it inherits from the Thread class.
We expect from the thread in the run method, that it fetches new items from the queue, and that it ends itself if there are no items left. This is common for all our possible threads, therefore we can implement this in an upper class for 'controllable' threads.
If there are no more items to process, the ControllableThread can terminate itself, but has to inform the ThreadController about this. In the webcrawler scenario, this is important when all URLs for the link depth of 2 are processed and the next deeper level is reached. The ThreadController is now responsible for shifting the queues and starting new threads as needed.
During program execution, it might sometimes be necessary that a 'working thread' tells the 'main thread' what it does at the moment. It the web crawler application eg. the user might be interested in what page the crawler is currently visiting. For this purpose the MessageReceiver interface exists. The main class can register itself or another class as a message receiver. The message receiver class is then notified, when a thread does something, a thread is terminated or all threads are terminated. Reconsider that in the object oriented paradigm calling a method is equivalent to sending a message. In this scenario it gets quite clear why this is the case.
The two main tasks of a webcrawler are of course saving data from a URL to a file and extracting hyperlinks. Because of Javas URL class, both tasks are rather simple. Although in this case this might not be the proper object oriented approach, I decided to implement these tasks in static methods in the SaveURL class. This class contains only static methods. A main method is supplied, so that the class can be used in a stand-alone version to save a file from a given URL. All methods for saving data from a URL into a file are fairly short and self-explanatory. I provided several variations in the implementation for writing the contents of the URL to a String, an OutputStream or a Writer.
Note that is not necessary for each method to 're-invent the wheel.' For example, the getURL method that returns the URL's contents as a String creates a StringWriter and calls the saveURL method to write the URL's contents to a Writer.
When doing input/output operations, it is almost always a good idea to use buffering, because transferring data 'en-bloc' is more efficient than transferring data byte by byte. Java provides buffering off the shelf. In the saveURL(URL, Writer) method Java's BufferedInputStream is used for reading from the URL. In the saveURL(URL, OutputStream) method buffering buffering is done through a byte array.
The methods that we will actually use for webcrawling are the writeURLtoFile method in our webcrawler are the writeURLtoFile and the
Using Java's String class, extracting hyperlinks from a web page is almost trivial. We use the getURL method mentioned above to retrieve a String object containing the complete HTML page. The basic idea is to use the indexOf method of the String class to extract the beginning '≶a href'. A couple of other indexOf-calls and a StringTokenizer extract the URL and the link text from the HTML tag. However, for this approach to work correctly, we first have to convert the 'raw' HTML page from its mixed-case form into a form that is only lower case to allow easy extraction. We use the toLowerCase method of the String class to do this. We also convert all whitespaces (i.e. tabs, line breaks etc.) into simple spaces using the replaceAll method. This is necessary because we might get confused if e.g. in the HTML page the '≶a' is followed by a line break instead of a blank.
The extractLinksWithText method in the SaveURL class stores URL/text pairs in a Map, extractLinks stores the URLs only in a Vector.
Note that we could also have used more elaborate regular expressions instead of a bunch of indexOf calls. The interested reader who is familiar with regular expressions should feel free to regard rewriting the SaveURL class using the String.split method as an exercise. ;-) Note also that the extractLink-methods at the moment do not know about HTML comments. If in an HTML page a link that is commented out occurs, our methods extract them as well as if it was an ordinary link. Whether you regard this a bug or a feature is up to you. ;-)
Now we have all parts we need to build a web crawling application. If you look at the flow chart again, you should now be able to understand which part of the program does what and how the parts fit together.
The two sample applications that are included are the 'PSucker' and the 'WSDLCrawler'. The 'PSucker' saves image and video files from the web based on their file name extension. The 'WSDLCrawler' saves WSDL (Web Service Description Language) files from the web, not based on the file name extension but on the content. A look into the WSDLCrawlerThread and the PSuckerThread classes illustrates the difference between the two approaches.
Please note that at this stage the crawler does neither care about robots.txt-files on the remote host nor about meta-tags. A web site provider could use either of these methods to prohibit robots from crawling their pages. The crawlers commonly used by search engines and other commercial web crawler products usually adhere to these rules. Because our tiny webcrawler here does not, you should use it with care. Do not use it, if you believe the owner of the web site you are crawling could be annoyed by what you are about to do.
This section describes in brief how to install the provided webcrawler, how to invoke it and how to customize it.
javac
ie/moguntia/webcrawler/*.java from the top directory.If you have completed the steps above and you did not receive any error messages, then, congratulations, your web crawler is ready to use.
You can invoke the webcrawler by typing
java
ie.moguntia.webcrawler.PSucker url filenamePrefix [maxLevel
[maxDoc [maxThreads]]]
The parameters are as follows:
The WSDLCrawler sample application is invoked byjava
ie.moguntia.webcrawler.PSucker url filenamePrefix [maxLevel
[maxThreads]].
Note that the maxDoc paramter is currently not implemented in WSDLCrawler.
The sample P-Sucker application crawls the web and saves all images and video files that are linked. (The P in P-Sucker stands for 'picture'.) Note that embedded graphics (with the img-tag) are not saved, only files that are linked. A standard use for such a program is e.g. crawling a friend's web page where his/her holiday pictures are stored. Usually these 'photo book' pages tend to have small 'preview' pictures and links to the full resolution images. In this usage scenario, the PSucker would save the full resolution images.
To customize your webcrawler, have a look into the WSDLCrawlerThread and the PSuckerThread classes. Near the top of the process method in both classes you will find the rules that determine if a file is saved, crawled for links, or both. In the PSuckerThread class, this is done simply by a list of file name extensions. In the WSDLCrawlerThread, the contents of the returned file are examined and the MIME type is checked.
If you want to create a 'vanilla' web crawler that saves every HTML page it finds, just throw out the test and always call SaveURL.writeURLtoFile. It is up to you if you find such an application useful. Because links are not adjusted when a HTML page is stored, you will be able to view the raw text of the downloaded page only, but links won't work and embedded images will not be downloaded. It is left as an exercise to the reader to implement this. However, there are web crawlers out there that do this sort of thing, e.g. wget. If you just want a plain webcrawler, you may want to use one of those tools instead, and use customizations of WSDLCrawler/PSucker only for special tasks.
I hope you have fun understanding what the source code provided here does. Please note that the code provided is in the public domain and there are no warranties whatsoever attached to it. If you have any questions, suggestions or comments, if you have found a bug or if you have made changes to code, I would appreciate if you send me a mail.